
Y. Wayne Wu
I am building the UX Research team at Workato. As a leader in the iPaaS sector, we are pushing boundaries in the Low-Code/No-Code movement and democratizing enterprise automation.
I received my Ph.D. degree in Human-Computer Interaction from the University of Illinois at Urbana-Champaign, working with Prof. Brian Bailey. Throughout my career, I've always been working at the intersection of the sciences and humanities and have been fascinated by how technology transforms human conditions and our society.
PUBLICATIONS

Better Feedback from Nicer People: Narrative Empathy and Ingroup Framing Improve Feedback Exchange
Y. Wayne Wu, Brian Bailey
The 23rd ACM Conference on Computer-Supported Cooperative Work and Social Computing - CSCW 2020
Online feedback exchange platforms enable content creators to collect a diverse set of design feedback quickly. However, creators can experience low quality and harsh feedback when using such platforms. In this paper, we leverage the empathy of the feedback provider to address both these issues. Specifically, we tested two narrative-based empathy arousal interventions: a negative experience and a design process narrative. We also examined whether ingroup framing further enhances the effects of empathy arousal. In a 3x2 online experiment, participants (n=205) wrote feedback on a poster design after experiencing one of the intervention conditions or a control condition. Our results show both the design process narrative and ingroup framing conditions significantly increased the feedback quality and effort invested in the task. The negative experience narrative condition had similar effects and participants reported significantly increased disapproval towards harsh feedback. We discuss the implications of our results for the design of feedback exchange platforms.

Y. Wayne Wu, Michael Gilbert, and Elizabeth Churchill
The 17th IFIP TC.13 International Conference on Human-Computer Interaction - INTERACT 2019
Web fonts quickly gained popularity among practitioners. Despite their wide-spread usage and critical role in design, there is a lack of empirical research regarding how practitioners select web fonts and what problems they encounter in the process. To fill this knowledge gap, we took a mixed-method approach to examine the salient factors and common issues in the typeface selection process. To understand the landscape of the problem, we first analyzed adoption data for Google Fonts, a representative online fonts directory. Then, we interviewed practitioners regarding their experience selecting web fonts and the problems they en-countered. Finally, we issued a follow-up survey to validate the qualitative findings. Our study uncovered how practitioners operationalized three salient factors --- affordability, functionality, and personality --- in the typeface selection process. Participants reported difficulty in finding typefaces that satisfy the functionality and personality needs. We discuss patterns that led to this difficulty and offered practical design guidelines that alleviated the identified issues.
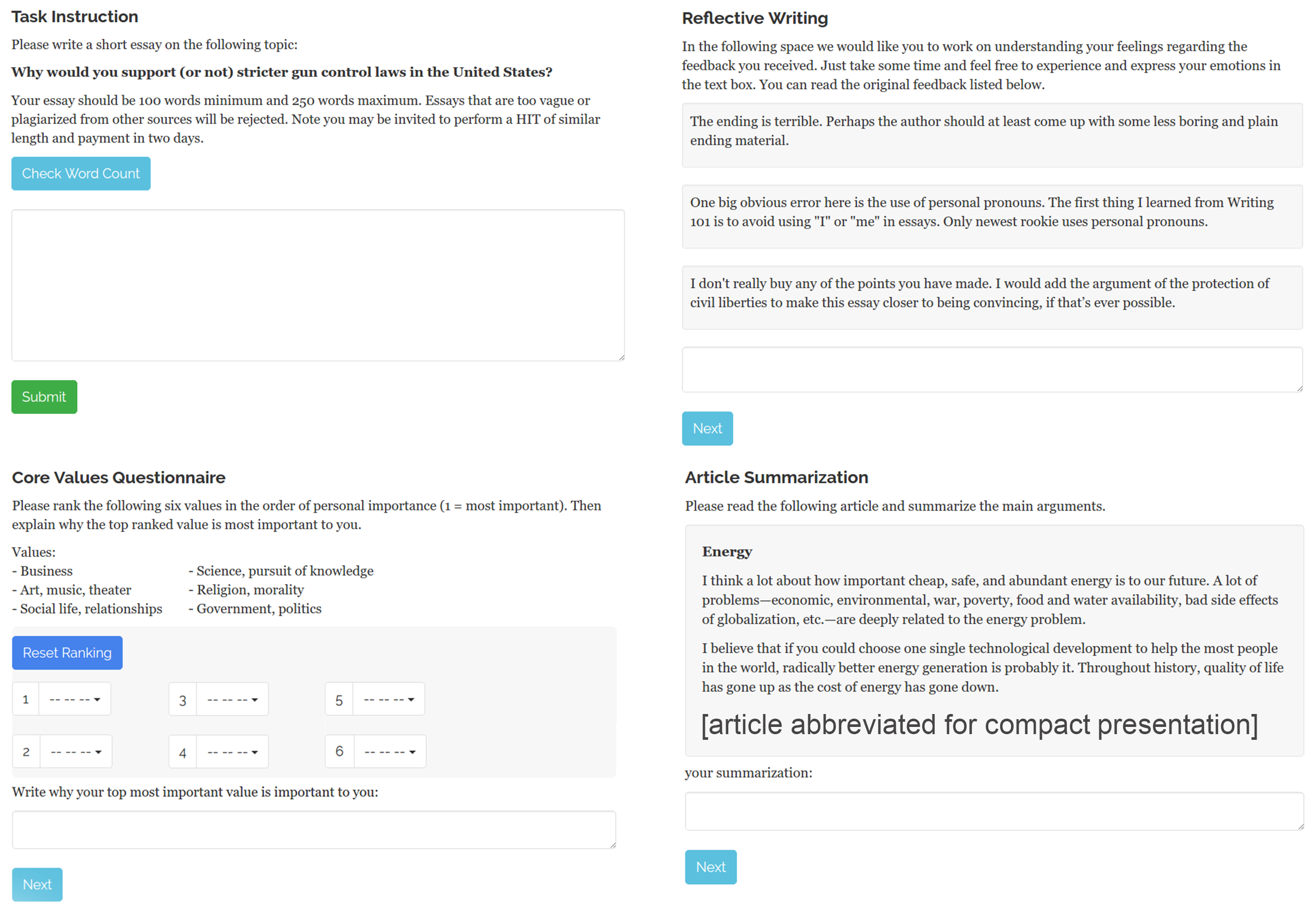
Soften the Pain, Increase the Gain: Enhancing Users’ Resilience to Negative Valence Feedback
Y. Wayne Wu, Brian Bailey
The 21st ACM Conference on Computer-Supported Cooperative Work and Social Computing - CSCW 2018
Content creators fear receiving unnecessarily harsh criticism when posting creative work in online platforms. We refer to feedback written in an unnecessary harsh tone as negative feedback. We conducted an online experiment to investigate the efficacy of three coping activities for mitigating the influence of negative feedback: self-affirmation, expressive writing, and distraction. Participants (N=480) received feedback sets with different balances of neutral and negative valence content and revised their essays after performing the assigned activity. We measured participants’ affective states, extents of revision, and their perceptions of the feedback and its providers. Our results showed even a small amount of negativity had significant adverse effects on all the measures. For the coping activities, we found that expressive writing encouraged essay revision, distraction improved affective states and feedback provider perception, and self-affirmation had no significant effects on the measures. Our results contribute further empirical knowledge of how negative valence feedback impacts content creators and how the coping activities tested mitigate these effects. We also offer practical guidelines regarding when and how to use the activities tested in online feedback platforms. [slides]
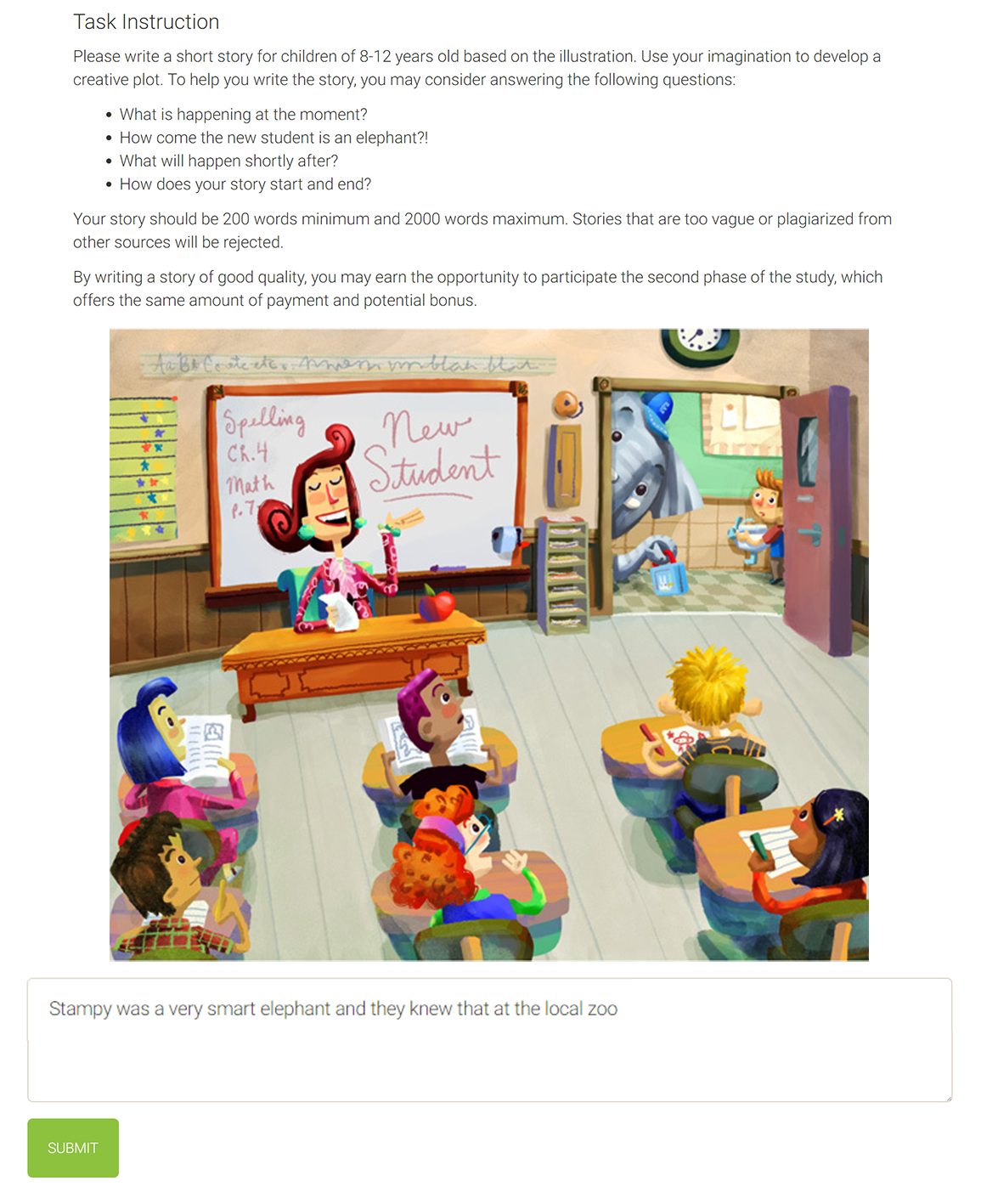
Bitter Sweet or Sweet Bitter? How Valence Order and Source Identity Influence Feedback Acceptance
Y. Wayne Wu, Brian Bailey
The 2017 ACM SIGCHI Conference on Creativity and Cognition - C&C 2017
Content creators are less receptive to feedback with negative valence, and such feedback is frequently received online. To address this problem, we propose a novel method that orders a set of feedback based on its valence; using the feedback with positive valence to mitigate the effects of the negative valence feedback. To test the method, participants (N=270) wrote a story for children based on a given illustration and then revised their story after receiving a set of feedback. The feedback set was delivered with different valence orders and with different source identity cues. We measured participants’ affective states, perceptions of the feedback and its source, revision extents, and story quality. Our main result is that presenting negative feedback last improved content creators’ affective states and their perception of the feedback set relative to placing the negative feedback in other positions. This pattern was consistent across all feedback source conditions. The work contributes a simple and novel way to order a set of feedback that improves feedback receptivity. [grad symposium] [slides]
Y. Wayne Wu, Brian Bailey
The 2016 CHI Conference on Human Factors in Computing Systems - CHI 2016
Crowd feedback services offer a new method for acquiring feedback during design. A key problem is that the services only return the feedback without any cues about the people who provided it. In this paper, we investigate two cues of a feedback provider – the effort invested in a feedback task and expertise in the domain. First, we tested how positive and negative cues of a provider’s effort and expertise affected perceived quality of the feedback. Results showed both cues affected perceived quality, but primarily when the cues were negative. The results also showed that effort cues affected perceived quality as much as expertise. In a second study, we explored the use of behavioral data for modeling effort for feedback tasks. For a binary classification, the models achieved up to 92% accuracy relative to human raters. This result validates the feasibility of implementing effort cues in crowd services. The contributions of this work will enable increased transparency in crowd feedback services, benefiting both designers and feedback providers. [slides]
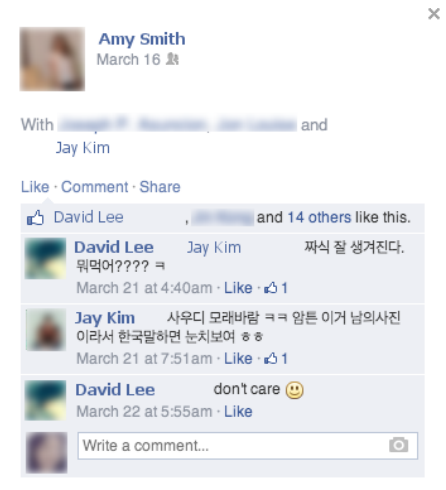
Ha Kyung Kong, Y. Wayne Wu, Brian Bailey and Karrie Karahalios
The 7th International Conference on Social Informatics - SocInfo 2015
Multilingual users of social networking sites (SNSs) write in different languages for various reasons. In this paper, we explore the language choice of multilingual Chinese and Korean students studying in the United States on Facebook. We survey the effects of collectivist culture, imagined audience, and language proficiency on their language choice. Results show that multilingual users use language for dividing and filtering their imagined audience. Culture played two contrasting roles; users wanted to share their culture in English but share their emotions in their native language. Through this work, we hope to portray language choice not as a tool for exclusion but of consideration for the potential audience and adherence to one's culture. [slides]
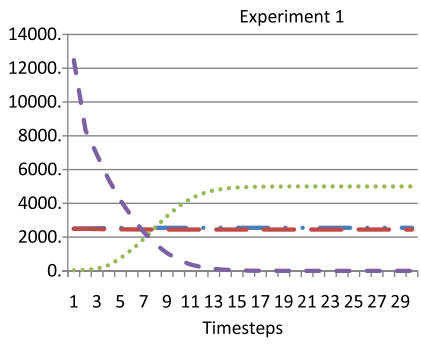
How Behaviors Spread in Dynamic Social Networks
Yu Zhang, Y. Wayne Wu
Computational and Mathematical Organization Theory Vol. 18 (4), 2012
In this paper, we explore how decentralized local interactions of autonomous agents in a network relate to collective behaviors. Earlier work in this area has modeled social networks with fixed agent relations. We instead focus on dynamic social networks in which agents can rationally adjust their neighborhoods based on their individual interests. We propose a new connection evaluation theory, the Highest Weighted Reward (HWR) rule: agents dynamically choose their neighbors in order to maximize their own utilities based on rewards from previous interactions. We prove that, in the two-action pure coordination game, our system would stabilize to a clustering state in which all relationships in the network are rewarded with an optimal payoff. Our experiments verify this theory and also reveal additional interesting patterns in the network.
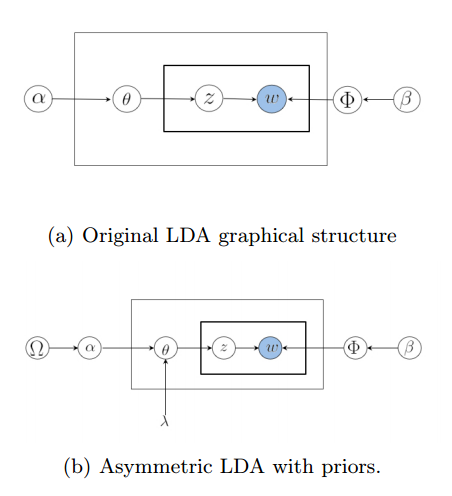
Incorporating Meta Data into Dynamic Topic Analysis
Tianxi Li, Branislav Kveton, Y. Wayne Wu, Ashwin Kashyap
The 9th UAI Conference on Bayesian Modeling Applications Workshop - BMAW 2012
Everyday millions of blogs and micro-blogs are posted on the Internet These posts usually come with useful metadata, such as tags, authors, locations, etc. Much of these data are highly specific or personalized. Tracking the evolution of these data helps us to discover trending topics and users’ interests, which are key factors in recommendation and advertisement placement systems. In this paper, we use topic models to analyze topic evolution in social media corpora with the help of metadata. Specifically, we propose a flexible dynamic topic model which can easily incorporate various type of metadata. Since our model adds negligible computation cost on the top of Latent Dirichlet Allocation, it can be implemented very efficiently. We test our model on both Twitter data and NIPS paper collection. The results show that our approach provides better performance in terms of held-out likelihood, yet still retains good interpretability.
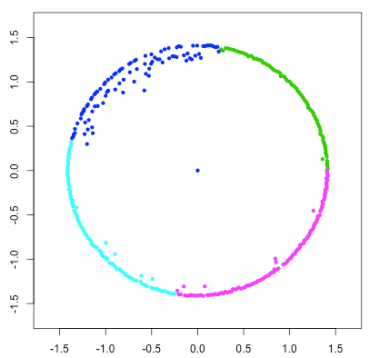
Twitter Hash Tag Prediction Algorithm
Tianxi Li, Y. Wayne Wu, Yu Zhang
The 2011 International Conference on Internet Computing - ICOMP 2011
Social media has demonstrated quick growth, in both directions of becoming the most popular activities in internet and of attracting scientific researchers to get better insights into the understanding into the underlying sociology. Real time micro-blogging sites such as Twitter, Flickr and Delicious use tags as an alternative to traditional forms of navigation and hypertext browsing. The tag system of those micro-blogging sites has unique features in that they change so frequently that it is hard to identify the number of clusters and so effectively carry out classification when new tags can come out at any time. In this paper, we propose to use Euclidean distance between points as the measurement of their similarity. Our method has advantages in easy data storage and easy accommodation to personal settings. In experiment, we compare our model with other classification functions and show that our model maintains a false positive rate lower than 15%. Our work is relevant for researchers interested in navigating of emergent hypertext structures, and for engineers seeking to improve the navigability of social tagging systems.
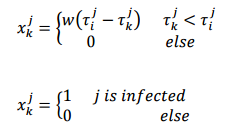
Two Models for Inferring Network Structure from Cascades
Dakan Wang, Y. Wayne Wu, Yu Zhang
The 2011 International Conference on Internet Computing - ICOMP 2011
In many real-world scenarios, the underlying network over which the diffusions and propagations spread is unobserved, i.e. the edges of the network are invisible. In such cases, we can only infer the network structure from underlying observations. The goal of this paper is to find a model that generates realistic cascades with observed data, so that it can help us with link prediction and outlier detection. For this purpose, we investigate two cascade models. The first model is a naive two-class cascades that includes one class of positive (infected) nodes and one class of negative (uninfected) nodes. In this model, we use the sparse logistic regression method to infer network edges. In the second model, we discard all negative training nodes and treat the whole network as a single class. In this model, we use the one-class Support Vector Machines to predict underlying edges. Experiments show that even if we discarded all negative training instances, we can still infer network edges accurately.
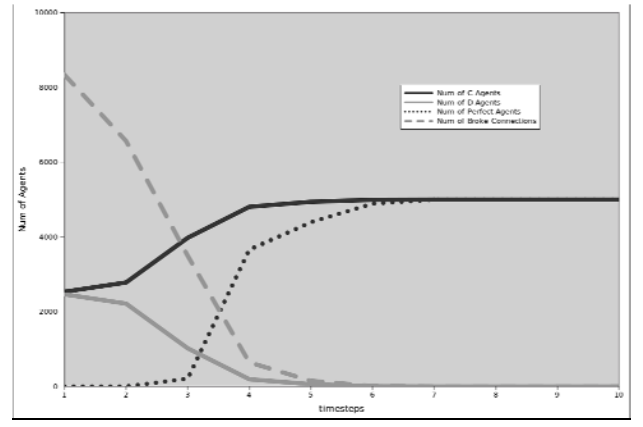
Pattern Analysis in Social Networks with Dynamic Connections
Y. Wayne Wu, Yu Zhang
The 4th International Conference on Social Computing, Behavioral-Cultural Modeling and Prediction - SBP 2011
In this paper, we explore how decentralized local interactions of autonomous agents in a network relate to collective behaviors. Most existing work in this area models social network in which agent relations are fixed; instead, we focus on dynamic social networks where agents can rationally adjust their neighborhoods based on their individual interests. We propose a new connection evaluation rule called the Highest Weighted Reward (HWR) rule, with which agents dynamically choose their neighbors in order to maximize their own utilities based on the rewards from previous interactions. Our experiments show that in the 2-action pure coordination game, our system will stabilize to a clustering state where all relationships in the network are rewarded with the optimal payoff. Our experiments also reveal additional interesting patterns in the network.
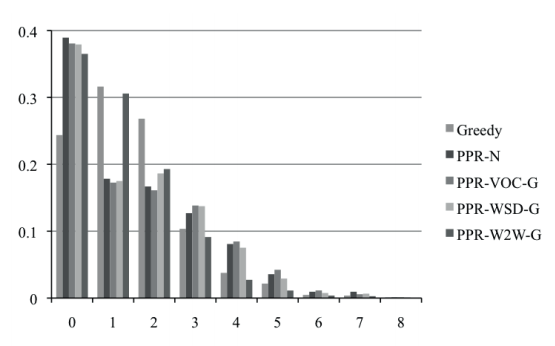
Automatic Reduction of a Document-Derived Noun Vocabulary
Sven Anderson, Rebecca Thomas, Camden Segal and Y. Wayne Wu
The 24th International Florida Artificial Intelligence Research Society Conference - FLAIRS 2010
We propose and evaluate five related algorithms that automatically derive limited-size noun vocabularies from text documents of 2,000-30,000 words.The proposed algorithms combine Personalized Page Rank and principles of information maximization, and are applied to the WordNet graph for nouns. For the best-performing algorithm the difference between automatically generated reduced noun lexicons and those created by human writers is approximately 1-2 WordNet edges per lexical item. Our results also indicate the importance of performing word-sense disambiguation with sentence-level context information at the earliest stage of analysis.

In this project, we explore how decentralized local interactions of autonomous agents in a network relate to collective behaviors. Most existing work in this area models social network in which agent relations are fixed; instead, we focus on dynamic social networks where agents can rationally adjust their neighborhoods based on their individual interests. We propose a new connection evaluation rule called the Highest Weighted Reward (HWR) rule, with which agents dynamically choose their neighbors in order to maximize their own utilities based on the rewards from previous interactions. We show that in the 2-action pure coordination game, our system will stabilize to a clustering state where all relationships in the network are rewarded with the optimal payoff. Preliminary experiments verify this theory and also reveal additional interesting patterns in the network.
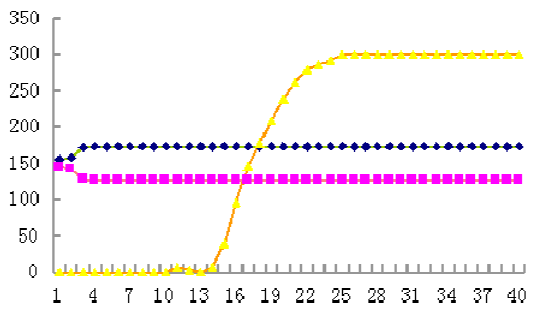
Stability Analysis in Dynamic Social Networks
Y. Wayne Wu and Yu Zhang
The 2010 Spring Simulation Multiconference - SpringSim 2010
In this paper, we address the problem that how could the decentralized local interactions of autonomous agents generate social norms. Different from the existing work in this area, we focus on dynamic social networks that agents can freely change their connections based on their individual interests. We propose a new social norm rule called Highest Weighted Neighborhood (HWN) that agents can dynamically choose their neighbors to maximize their own utility through all previous interactions between the agents and these neighbors. Comparing with the traditional models that networks usually are static or agents choose their neighbors randomly, our model is able to handle dynamic interactions between rational selfish agents. We prove that in the 2-action pure coordination games, our system will stabilize in a clustering state and at that time all relationships in the network are rewarded the optimal payoff. Our preliminary experiments verify the theory.
Last Updated: September 2022